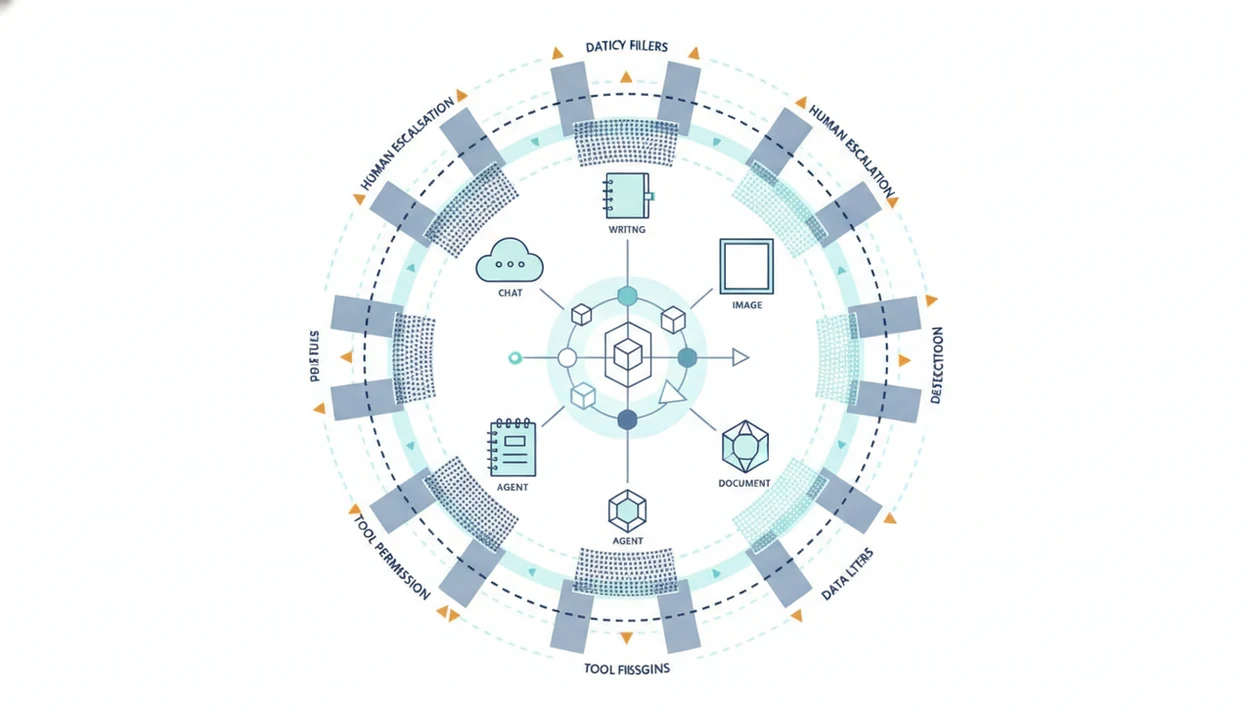
AI Agent Guardrails Definition for Production Workflows
AI agent guardrails are layered safety and governance controls around agent behavior before, during, and after an agent acts. They define which requests are allowed, which tools can be used, what data can be touched, and when a human review step is required.
In production, guardrails do not sit in one place. They apply when the user submits a request, when the system classifies intent, when the agent calls a tool, and when the final answer is checked. Tools like AIACI use this pattern across chat, writing, image, document, and detection agents so each specialized agent stays inside its workflow fit.
The core categories are policy rules, input filters, tool permissions, output validation, logging, and escalation. A scanned receipt crooked on screen needs different controls than a legal clause search or an image prompt.
Five AI Agent Guardrails Facts Teams Should Know
- Guardrails are layered controls, not one filter. A profanity checker on the final answer is not enough for a production agent.
- Guardrails must cover the full workflow. Prompt input, tool use, routing, output validation, and escalation all need separate checks.
- Multi-agent systems need agent-aware rules. A document-analysis agent should not follow the same policy as an image-generation agent.
- Privacy, security, compliance, and user trust are primary reasons to implement guardrails. According to the 2022 MIT Sloan Management Review and Boston Consulting Group report on responsible AI, 78% of companies using AI called responsible-AI practices very or extremely important, but only 20% had fully implemented them: https://sloanreview.mit.edu/projects/the-state-of-responsible-ai-in-2022/.
- Guardrails must be monitored and updated. Models change, users adapt, and prompt-injection attempts get more creative.
The messy work pile matters here: meeting notes, a half-written brief, screenshots, and a support ticket rarely belong in one undifferentiated chatbot.
How AI Agent Guardrails Work Across Inputs, Tools, and Outputs
AI agent guardrails work by placing checks at each stage of the agent lifecycle: user request, classification, routing, tool authorization, response generation, output validation, and logging. The point is to catch risk before it becomes an action, not after a bad answer has already reached the user.
Some controls are deterministic rules. For example, “never expose API keys” or “block export of credentials” can be written as hard policy. Others use model-based classifiers that estimate intent, sensitivity, or policy risk. In plain language, the system is asking, “What kind of task is this, and where should it go?”
Semantic routing can send a routine draft to a writing agent, a chart screenshot to an image or vision workflow, or a risky medical request to human review. Guardrails can block, rewrite, redact, ask for clarification, or escalate.
For production teams, guardrails usually work best when they sit at every handoff, because agent errors often happen between steps rather than inside one model response.
Routers are still probabilistic. Watch them. Set minimum routing-confidence thresholds, log every override, and review samples where the router sent work to the wrong agent. For policy categories, many teams map guardrails to NIST AI RMF functions and OWASP LLM Top 10 risks: https://www.nist.gov/itl/ai-risk-management-framework and https://owasp.org/www-project-top-10-for-large-language-model-applications/.
AI Agent Guardrails Requirements Before Deployment
Before deployment, teams should prepare the policy, data, tools, owners, and metrics that guardrails will enforce. A guardrail system cannot be clearer than the operating rules behind it.
- Acceptable-use policy: Define allowed tasks, prohibited requests, high-risk domains, and refusal language in plain English.
- Sensitive data map: Label PII, credentials, medical data, financial data, confidential documents, and customer records.
- Tool inventory: List every API, file store, database, browser action, and external system the agent can reach. This belongs next to your AI agent tool calling plan.
- Owner model: Assign product, legal, security, engineering, and operations owners for policy changes and incidents.
- Initial metrics: Track policy-violation rate, false-positive rate, escalation volume, and incident response time.
McKinsey reported in 2023 that 55% of organizations had at least one AI-related cyber or privacy risk event in the prior three years: https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai-in-2023-generative-ais-breakout-year. That number should make tool permissions feel less optional.
Five Steps to Use AI Agent Guardrails in a Production Agent Network
Use AI agent guardrails by defining policy first, then enforcing it across routing, tools, outputs, and review loops. In an AI agent network, the setup should follow the work, not a generic safety checklist.
- Set policy rules for allowed and disallowed tasks. Define what chat, writing, image, document, and detection agents may handle.
- Filter and classify user inputs before routing. Detect prompt injection, sensitive data, unsafe image requests, and ambiguous intent.
- Restrict tools, APIs, files, and external actions by agent role. A writing agent should not inherit document-agent file permissions.
- Validate, redact, or rewrite outputs before delivery. Check for hallucinated claims, leaked PII, unsafe instructions, and policy conflicts.
- Review logs, escalations, and metrics to tune the guardrails. Compare blocked requests with user appeals and confirmed incidents.
In AIACI, guardrails should make task routing safer across chat, writing, image generation, document analysis, and detection agents. The goal is reviewable handoffs and bounded permissions, not unattended authority over sensitive work.
AI Agent Guardrails Policy Rules for Safer Task Routing
How should policy rules guide AI agent task routing? Policy rules should act as the source of truth for allowed actions, disallowed requests, and escalation thresholds across every specialized agent.
A chat agent can answer general workflow questions. A writing agent can restructure a messy outline on sticky notes. An image agent can generate a visual concept from a rough sketch photographed on a phone. A document agent can summarize uploaded files, but it should not extract credentials or invent legal conclusions from a contract.
Routing policies should separate low-risk, high-risk, ambiguous, and prohibited tasks. Low-risk requests can move directly to the right agent. Ambiguous requests should ask a clarifying question. High-risk legal, medical, financial, or compliance requests should escalate or return safe general information. Prohibited requests should be refused.
Policy rules should be readable by product, legal, security, and operations teams. If only one engineer understands the rule, it is not ready for production.
AI Agent Guardrails Filters for Inputs, Outputs, and Tool Calls
AI agent guardrail filters enforce policy at specific points in the workflow. Output filters help, but they are insufficient when the agent can retrieve files, call APIs, or route a task before the final response exists.
| Filter type | What it checks | Action it can trigger |
|---|---|---|
| Input filter | Prompt injection, unsafe requests, PII, credentials, high-risk intent | Block, redact, classify, or ask for clarification |
| Output filter | Hallucinated claims, unsafe instructions, PII leaks, policy conflicts | Rewrite, remove, cite-check, or escalate |
| Tool-call filter | Unauthorized API calls, risky parameters, external actions | Deny, require approval, or log for review |
| Retrieval filter | Sensitive documents, irrelevant chunks, access-boundary violations | Exclude, mask, or limit retrieval |
| Routing filter | Agent mismatch, unsafe image requests, domain risk | Send to another agent or human review |
The soft keyboard tapping cautious edits is familiar here. A detector score can appear, but someone still has to read the flagged sentence.
AI Agent Guardrails Review, Logging, and Escalation Loops
Human review and observability make guardrails auditable. They also give teams a way to improve rules after real users hit edge cases.
- Escalation paths: Agents should hand off to a human, supervisor workflow, or different specialized agent when the domain is risky, confidence is low, or intent is unclear.
- Centralized logging: Store prompts, classifications, routing decisions, tool calls, outputs, and policy outcomes in one reviewable place.
- Replay workflows: Let reviewers rerun incidents against updated policies to see whether the same failure would happen again.
- Anomaly detection: Flag repeated policy-boundary attempts, unusual tool-call patterns, and sudden spikes in blocked requests.
The OECD AI Incidents Monitor had logged more than 1,000 AI-related incidents and controversies worldwide by 2024: https://oecd.ai/en/incidents. That is the practical case for logs, not just dashboards. An operations dashboard on a wall screen is only useful if it shows what changed and why.
AI Agent Guardrails Mistakes That Break Safe Workflows
The most common guardrail mistake is treating safety as a content filter on the final answer. That misses tool calls, retrieval errors, routing mistakes, and unauthorized data exposure.
Another mistake is assuming guardrails remove the need for human review. They reduce risk, but they do not erase judgment. A founder pacing with a phone headset during a customer incident does not care that the filter “mostly worked.”
Teams also break safe workflows by using one generic configuration across every agent. Image generation, document analysis, detection, and drafting have different failure modes. The broader pattern is covered in AI agent failure modes.
Rules can also become too strict. If every ordinary request escalates, users route around the system. Skipping tool and API permissions is worse. It lets a polite-looking prompt trigger actions the agent should never control.
Measure false positives, false negatives, and policy-violation trends. For launch, review at least 50 blocked requests, 50 allowed requests, and every human-escalated case from the first production week. That small audit catches brittle rules faster than a dashboard average. Otherwise, the team is guessing.
AI Agent Guardrails Verification Metrics for AIACI Teams
Teams know guardrails are working when metrics show fewer unsafe outcomes without blocking legitimate work. Verification should be split by agent type because a document agent and an image agent fail in different ways.
- Safety metrics: Block rate, escalation rate, unsafe tool-call rate, PII leak rate, and confirmed policy-violation rate.
- Quality metrics: False-positive rate, false-negative rate, hallucination rate, user appeal rate, and reviewer override rate.
- Test methods: Red-team testing, scenario simulation, prompt-injection testing, replay review, and policy audits.
- Agent-level views: Track document extraction errors separately from writing hallucinations or detection-score disputes.
Pew Research Center found in 2023 that 52% of U.S. adults were more concerned than excited about AI in daily life: https://www.pewresearch.org/internet/2023/08/28/growing-public-concern-about-the-role-of-artificial-intelligence-in-daily-life/. That concern raises the bar for visible safeguards. For AIACI teams, guardrail metrics belong next to AI agent evaluation, not in a separate trust spreadsheet.