AI Agent Evaluation Definition and Success Criteria
AI agent evaluation is the structured process of testing whether an AI agent can complete real tasks correctly, safely, quickly, and within acceptable cost. A chatbot answer can be graded by reading the final response; an agent workflow must also be judged by the route it chose, the tools it used, and the steps it took.
A passing agent should prove task completion, correct routing, safe tool use, factuality, latency, cost control, and user satisfaction. The messy work pile matters here: meeting notes, a half-written brief, screenshots, and a support ticket should not all be treated as the same generic chat request.
AIACI is an AI agent app for mobile users and teams that routes chat, writing, image, document, and detection requests to specialized agents. For evaluation, that means AIACI should be judged on the handoff path as well as the final answer: whether the right agent received the task, used the right inputs, and returned a usable result.
AI Agent Evaluation at a Glance: 5 Facts Teams Need
- AI agent evaluation must inspect intermediate steps. Routing decisions, tool calls, retrieved context, and reasoning traces can fail even when the final answer sounds confident.
- Test suites must mirror real work. Include common user paths, edge cases, missing context, and known failure modes, not only tidy prompts written by the eval team.
- Multi-agent networks need layered metrics. Measure router accuracy, each specialized agent’s skill quality, and end-to-end task success separately.
- Automated benchmarks need human review. Regression tests catch repeated failures, but reviewers still need to read subjective outputs like tone rewrites or image usefulness.
- Evaluation is continuous. Models, tools, prompts, and user behavior shift after launch, so a passed test set can become stale.
The pocket check is real. A user staring at five nearly identical chat app icons on an iPhone home screen wants the right workflow, not another vague answer box.
How AI Agent Evaluation Works in a Multi-Agent Network
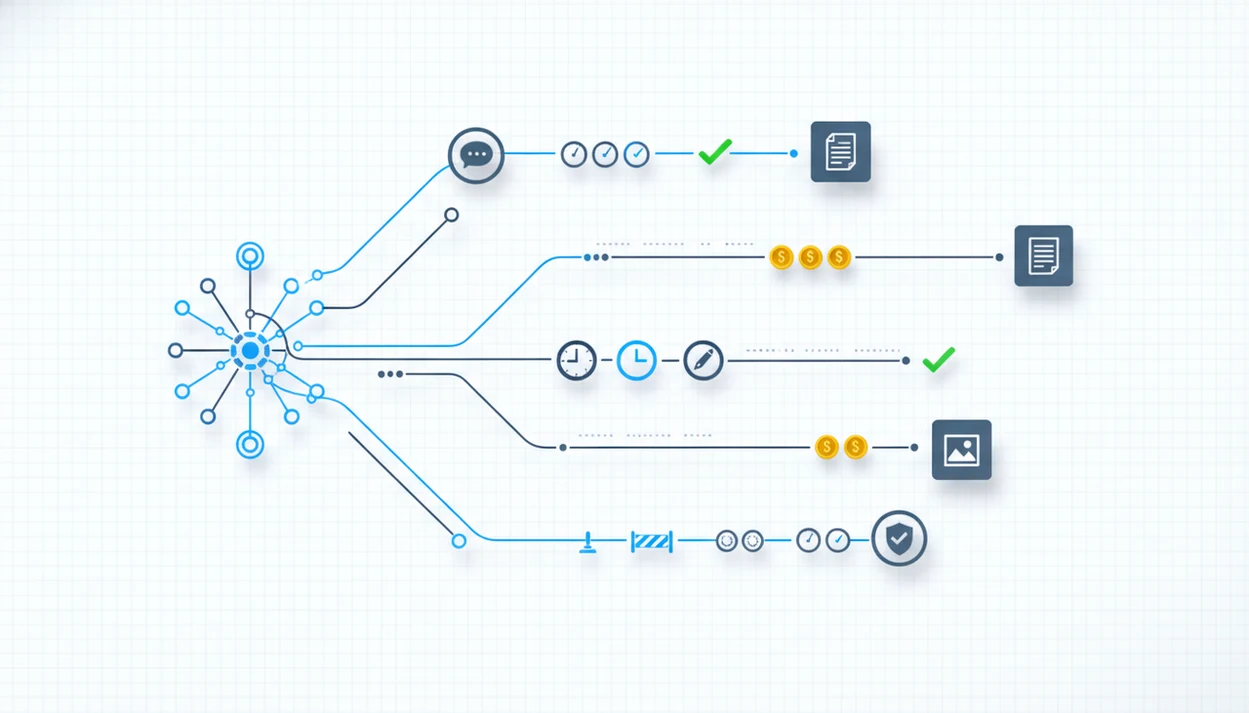
AI agent evaluation works by turning each user task into a test case with input, expected route, allowed tools, expected outcome, scoring rubric, and trace logs. In a multi-agent system, one score for the final answer is too thin.
End-to-end evaluation asks, “Did the user get the right result?” Step-level evaluation asks, “Did the system choose the right route, plan safely, call the right tool, use the right context, and synthesize the response correctly?” Both are needed. A document summary that looks fine may have skipped the key attachment, or an image prompt may have been routed to a writing agent first.
In AIACI, a mixed request might move between chat, writing, image, document, and detection agents. Each handoff needs a score. For production teams, step-level trace scoring is often more useful than final-answer grading because it shows where the workflow broke.
AI Agent Evaluation Requirements Before You Start
Before building an eval suite, gather the inputs that make testing resemble production. A clean spreadsheet of invented prompts is not enough once users upload real files or ask from a phone with half the context missing.
- Representative task inventory: Pull tasks from product analytics, support tickets, sales calls, and real user sessions. Include “summarize this PDF,” “rewrite this paragraph,” and “which agent should handle this?”
- Golden test set: Define expected outcomes, acceptable variations, and unacceptable failures. The scanned receipt crooked on screen should still produce the right totals or a clear refusal.
- Trace and telemetry access: Capture routes, tool calls, retrieved documents, latency, cost, model version, prompt version, and errors.
- Human review guidelines: Set rubrics for writing quality, image usefulness, tone, and ambiguity.
- Risk taxonomy: Track hallucinations, privacy leakage, unsafe actions, policy violations, and wrong routing. Related release rules belong in AI agent guardrails.
Step 1: Map AI Agent Tasks to Measurable Outcomes
Map agent tasks by skill first, then attach pass conditions to each skill. Vague goals like “make the agent smarter” do not survive release review.
- Group tasks by skill: Sort examples into chat, writing, image generation, document analysis, detection, and routing.
- Define the required outcome: A document agent must summarize the source accurately; a writing agent must follow tone and length constraints.
- Allow controlled variation: A mobile email draft may vary in wording if it keeps the sender’s intent, facts, and requested tone.
- Mark hard failures: Wrong routing, fabricated citations, unsafe tool calls, leaked private data, or ignored constraints should fail the test.
- Record the evidence: Save the prompt, expected route, output, trace, reviewer note, and score.
For document analysis, we like watching the page count finish loading after dragging in a PDF. That pause reminds the team that evaluation starts before the answer appears.
Step 2: Build AI Agent Benchmarks from Real Scenarios
How do you build AI agent benchmarks that reflect production usage? Start with realistic user scenarios, then add ambiguity, missing context, long inputs, adversarial prompts, and tool failures.
Public benchmarks can be useful for baseline comparison, but they rarely match your product’s upload boundaries, routing rules, or user expectations. A useful benchmark set includes happy paths, high-volume tasks, and high-risk tasks. Balance them. A common support summary may affect many users, while a rare privacy leak can carry much higher risk.
Scale is part of the case for serious evaluation. Pew Research Center reported in 2023 that 58% of U.S. adults had heard of ChatGPT, showing that agent-like AI interfaces were moving into mainstream awareness (https://www.pewresearch.org/short-reads/2023/05/24/a-majority-of-americans-have-heard-of-chatgpt-but-few-have-tried-it-themselves/). As more users treat agents as normal software, benchmark coverage needs to move beyond demo prompts.
Printer-warm pages stacked by a keyboard tell a different story than a three-line synthetic prompt.
Step 3: Score AI Agent Metrics That Matter
Score final success separately from path quality, safety, speed, and cost.
End-to-end agent metrics
| Metric | What it measures | Example pass signal |
|---|---|---|
| Task success rate | Whether the full user goal was completed | The support ticket summary is accurate and actionable |
| User satisfaction | Human preference or rating | Reviewer chooses the agent output over baseline |
| Safety compliance | Policy and risk behavior | The agent refuses unsafe requests correctly |
| Cost per successful task | Spend tied to useful completion | Lower cost without more failures |
| Escalation rate | Need for human or fallback handling | Ambiguous cases escalate instead of guessing |
Step-level agent metrics
| Metric | What it measures | Example pass signal |
|---|---|---|
| Routing accuracy | Correct specialized agent, tool, or workflow | Image prompt goes to image generation |
| Tool-call precision | Correctness of tool calls made | No unnecessary database lookup |
| Tool-call recall | Needed tool calls not missed | Retrieval runs before document answer |
| Retrieval relevance | Quality of context used in RAG | Source passages match the question |
| Hallucination rate | Unsupported claims | No invented dates or file contents |
| Path efficiency | Avoided wasteful steps | Fewer retries with same outcome |
Step 4: Review AI Agent Traces and Tool Calls
Trace review catches failures that final-answer grading misses. Inspect the router choice, plan, retrieved context, tool selection, tool arguments, retries, fallback behavior, and final synthesis.
A final answer may look plausible because the model guessed well. That is still a bad path if it chose the wrong specialized agent, skipped retrieval, called a tool with unsafe arguments, or used stale context. One route can be lucky today and expensive tomorrow.
Look at the trace like a handoff log. Did the routing layer send the request to document analysis, writing, detection, or chat? Did the tool call include the right file ID? Did fallback behavior trigger when the tool timed out? LLM-as-a-judge can help triage thousands of outputs, but it is not enough without ground truth and human review.
Tracked changes glowing in margins are a useful reminder: polished text can still hide a bad source trail.
Step 5: Add AI Agent Regression Tests to Releases
AI agent regression tests connect evaluation to release engineering. Run automated evals in CI/CD before shipping new models, prompts, tools, retrieval settings, or routing policies.
Gate deploys on high-priority benchmark thresholds and safety checks. If a new router improves image prompt handling but breaks document summaries, the release should pause. Canary rollouts help here. Send a small slice of traffic to the new version, compare outcomes, and keep rollback ready.
Track model version, prompt version, tool version, benchmark version, and evaluation date. A 2023 Stanford and UC Berkeley study found that GPT-4 behavior changed substantially on selected math, coding, and reasoning tasks over several months, which makes one-time evaluation unreliable (https://arxiv.org/abs/2307.09009). The exact task was narrow, but the lesson is broad: passing once is not enough.
Regression tests usually work best when they run before every release, while production monitoring catches failures caused by live traffic shifts. The operational payoff should be compared with AI agent ROI.
AI Agent Evaluation Mistakes and Verification Checks
The most common evaluation mistakes come from measuring what is easy instead of what breaks in production. A tidy final answer can hide wrong routing, unnecessary tool calls, or a privacy-sensitive retrieval step.
- Final-answer-only grading: Add trace checks for route, plan, tools, retrieved context, and fallback behavior.
- One generic benchmark score: Use product-specific tests beside public benchmarks.
- Uncalibrated LLM judging: Compare judge scores against known answers and human reviewers before trusting them.
- Ignored latency and cost: A correct answer that takes too long or costs too much may still fail.
- Thin user experience review: Test mobile flows, upload limits, error messages, and escalation paths.
Before release, verify known-answer tests, adversarial tests, human review samples, regression pass rate, monitoring alerts, and rollback plan. For recurring patterns, keep a catalog of AI agent failure modes.
Small misses compound. A Slack thread full of task links can turn one routing error into three confused handoffs.