The Detection Agent in Content Governance
The AIACI detection agent functions as a validation checkpoint in content governance workflows. It receives text input, measures a set of statistical features, and returns a confidence assessment indicating the likelihood of machine authorship. The agent does not make decisions—it provides data for human reviewers to act on. Organizations use detection agents to screen freelancer submissions, audit internal content pipelines, and verify compliance with policies governing AI-generated material. Detection results are probabilistic. False positives and false negatives occur. No detection tool provides definitive proof of authorship.
The agent's role is analogous to a quality inspector in manufacturing: it checks output against defined specifications and flags items that fall outside acceptable parameters. The specification, in this case, is the statistical profile of human-authored text. Content that matches machine-generated profiles gets flagged. Content that matches human profiles passes. The inspector does not decide what happens to flagged items—that responsibility belongs to the human reviewer with organizational context.

How Statistical Detection Works
The agent evaluates text across multiple statistical dimensions simultaneously. Perplexity measures how predictable word choices are—language models generate low-perplexity text because they select high-probability tokens, while human writers produce higher perplexity through unexpected word choices and idiosyncratic phrasing. Burstiness measures variation in sentence complexity—humans write in irregular patterns with short sentences punctuating longer ones, while AI generates more uniform distributions.
Vocabulary diversity captures the range of word choices within a passage. AI-generated text tends to stay within a narrower vocabulary band, selecting "safe" common words more frequently than humans who draw from personal vocabulary, domain jargon, and colloquialisms. The agent combines these features into a weighted assessment and returns a probability score. The threshold for flagging content is configurable by organizational policy—a 75% score might be acceptable for internal drafts but unacceptable for published articles.
Integration Into Content Workflows
The detection agent operates as one component in a multi-agent workflow on AIACI. A complete content governance pipeline: (1) content is generated or received, (2) the detection agent screens it and produces a score, (3) content above a defined threshold is routed for additional review, (4) content below the threshold proceeds to publication after human sign-off. This workflow applies whether content comes from freelancers, internal AI tools, or external contributors.
For teams producing AI-assisted content intentionally, the detection agent serves a different function: measuring how detectable the output is before external parties screen it. Generate content with the AI Writer, process it through the AI Humanizer, then validate with the detection agent. If scores remain high, additional human editing is needed. The agent provides feedback that informs the editing process rather than replacing it.
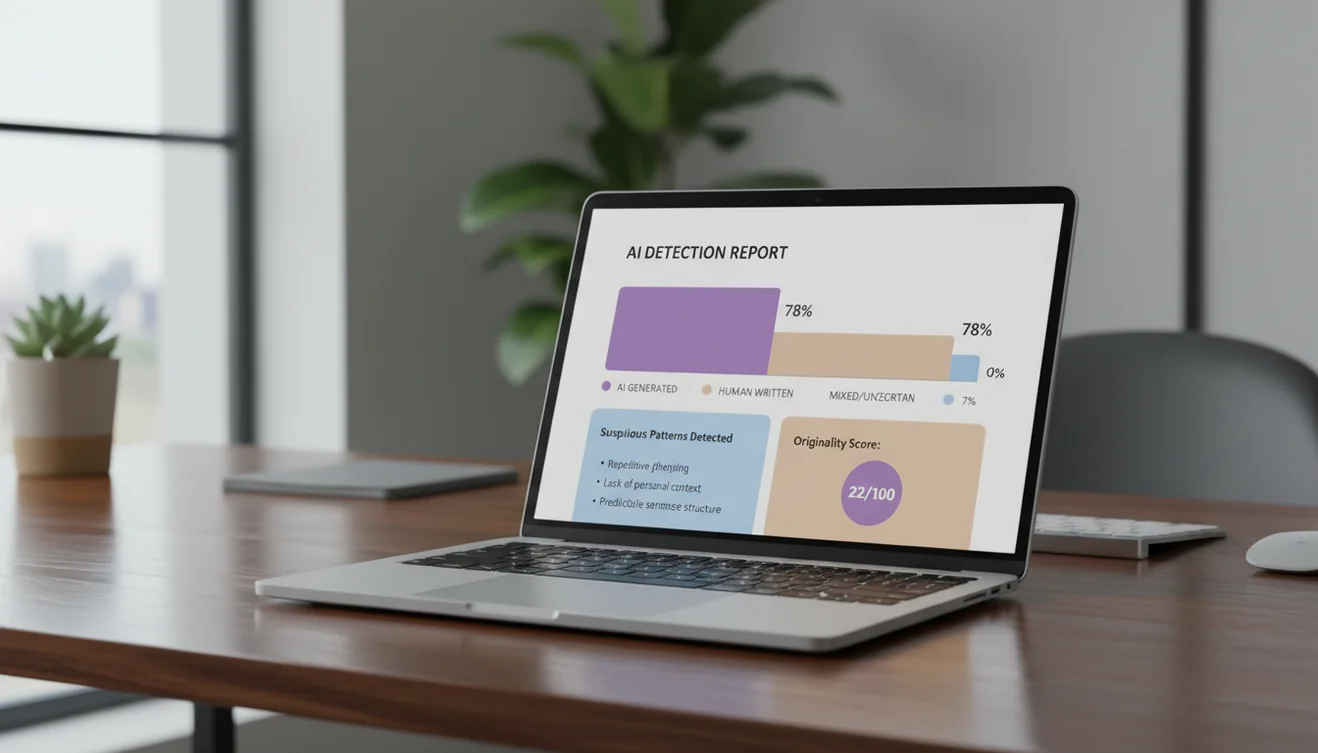
Interpreting Detection Results
A detection score of 90% does not mean the text was definitively written by AI. It means the text's statistical features align closely with patterns the agent associates with machine authorship. Human-written text that is formulaic, technical, or produced by non-native speakers can generate high scores without any AI involvement. Conversely, lightly edited AI text can score below detection thresholds.
Context matters more than scores. A freelancer who consistently delivers 95% AI-scoring content is worth investigating. A legal team whose compliance documents score 80% is producing formulaic writing that happens to trigger the detector. The agent provides a data point. The human reviewer provides judgment. Organizational policies define what actions follow from specific score ranges.
Limitations of Automated Detection
AI detection is not a solved problem. The technology operates on statistical correlation, not direct observation of how text was produced. Short text under 150 words lacks sufficient signal for reliable analysis. Heavily edited text—whether originally human or AI—may score unpredictably. Domain-specific writing in law, medicine, and engineering often reads as formulaic regardless of authorship and triggers false positives at higher rates.
Detection tools and generation tools exist in a continuous adaptation cycle. As generators improve, their output becomes harder to detect. As detectors adapt, generators adjust. Watermarking—embedding invisible statistical markers during generation—is a promising direction that bypasses the detection arms race by making authorship verifiable rather than inferred. Until watermarking is widely adopted, statistical detection remains the primary available method with its inherent limitations.

Common Misapplications
Using detection scores as sole evidence for punitive action—failing a student, terminating a freelancer, rejecting a submission—without additional context is the most common and most damaging misuse. Detection is a screening tool, not a forensic tool. Pair detection data with interviews, revision histories, style comparisons, and professional judgment before making consequential decisions based on AI detection results.
AIACI Detection Agent App
The detection agent is available free on the web and through the AIACI iOS app with unlimited analysis. The mobile app supports paste-and-analyze workflows with score history tracking. Download the AIACI app for unrestricted access to the detection agent and all platform tools.