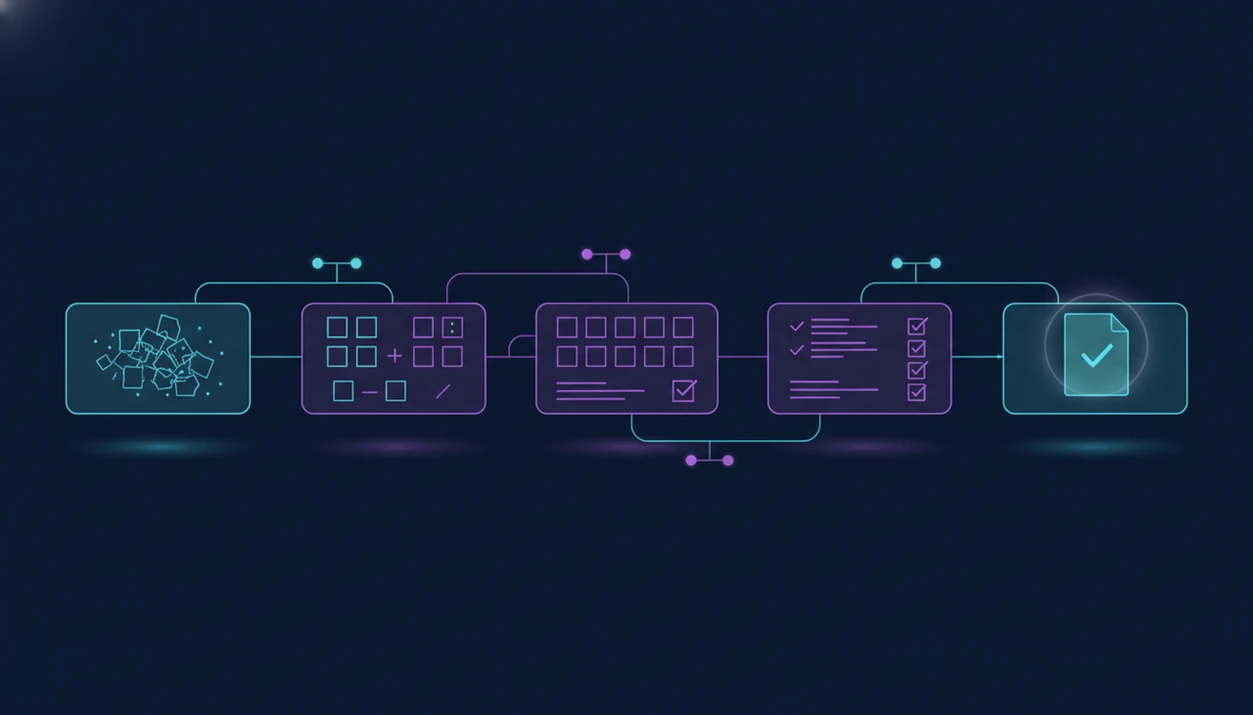
AI agent prompt chaining definition for multi-step work
AI agent prompt chaining is the practice of splitting one complex AI task into a sequence of smaller prompts, where each step feeds the next. It is not asking the same question again and again.
A single long prompt might ask for research, an outline, a draft, citations, tone edits, and final QA in one request. A chain separates those jobs. One step extracts facts. The next summarizes sources. Another builds the outline. Later steps draft, critique, and refine.
That structure matters when the work pile is messy: meeting notes, a half-written brief, screenshots, and a support ticket. The chain gives each agent step one job, then passes along a cleaner handoff. For research-heavy work, that usually beats a giant prompt because the review points are easier to see.
Five AI agent prompt chaining facts teams should know
- Prompt chaining is an agent architecture for decomposing complex work. It turns one broad request into smaller prompt steps with defined inputs and outputs.
- Prompt chaining helps research, drafting, and review because each step has one clear job. A research step should not also write the polished conclusion.
- Prompt chaining differs from one giant prompt because sequencing reduces ambiguity. The model handles a narrower instruction before the next step begins.
- Structured outputs make chains more reliable. Fields, outlines, scores, tables, and JSON-style handoffs are easier to reuse than loose paragraphs.
- Advanced platforms can route steps to specialized agents. A chain may use writing, document, image, chat, or detection agents rather than one general chatbot.
For teams, AI agent prompt chaining is often easier to audit than a single prompt because every intermediate output creates a review point.
How AI agent prompt chaining works behind the scenes
AI agent prompt chaining works as a directed workflow of prompts, outputs, checks, and next-step inputs. The technical idea is simple: each node produces an intermediate artifact, and the next node consumes that artifact under a narrower instruction.
The handoff is the fragile part. If Step 1 returns a rambling paragraph, Step 2 has to guess what matters. If Step 1 returns fields like `claim`, `source`, `confidence`, and `open question`, the next prompt has cleaner material. Less guessing.
Real chains also include branches. A document agent may extract contract clauses, then route low-confidence clauses to a review loop. A draft agent may send flagged sentences to a detector step before final revision. In production workflows, the routing layer matters because each agent needs a clear input, output, and fallback path.
A good AI agent network platform routes tasks to specialized agents for chat, writing, image generation, document analysis, and detection with a companion iOS app, not a promise that every workflow can run without review.
Requirements before building an AI prompt chain
Before building an AI prompt chain, define the final deliverable first. A “research brief for the sales team” needs different steps than a “public blog post with source checks.”
Prepare the source material, constraints, audience, format, and review criteria before writing prompts. That may mean collecting PDFs, call transcripts, product notes, and brand rules in one place. We’ve watched teams lose time because the first prompt never stated whether the output was for executives or support reps.
Assign a narrow role to each agent step: extractor, summarizer, outliner, drafter, critic, verifier. The first step needs extra care because early errors travel downstream. If a source summary is wrong, the draft may sound confident anyway.
Workflow discipline matters more now. The Stanford AI Index reported that 78% of organizations used AI in 2024, up from 55% in 2023, and 72% used generative AI in at least one business function source. McKinsey also reported broad growth in regular generative AI use during 2024 source.
How to use AI agent prompt chaining in a workflow
Use AI agent prompt chaining when the work has natural phases and review points. Research, draft, and review workflows are a clean starting place.
- Set the outcome. Define the final deliverable, audience, length, source rules, and approval standard.
- Split the task. Break the work into research extraction, source summary, outline, draft, critique, revision, and QA.
- Structure the handoff. Require fields such as claims, sources, open questions, risks, and next-step instructions.
- Route to the right agent. Use a document agent for PDFs, a writing agent for drafting, and a detection or review step for flagged text.
- Review the output. Check whether each step followed the prior handoff instead of inventing missing context.
- Reset failed steps. Stop the chain when a weak extraction, missing source, or bad assumption appears.
The pocket check is real. Someone staring at five nearly identical chat app icons on an iPhone home screen needs routing clarity, not another place to paste the same oversized prompt.
Research, draft, review prompt chain example
A practical research-to-review chain should show what each step receives and what it must hand off. The goal is not more steps. The goal is fewer hidden assumptions.
Sample chain map
| Step | Agent job | Input | Handoff output |
|---|---|---|---|
| 1. Research extraction | Pull key points from source material | PDFs, notes, transcript | Bullets with source labels |
| 2. Source summary | Group evidence by theme | Extracted bullets | Table of claims, sources, gaps |
| 3. Outline | Build structure | Claims table | Section outline with intent |
| 4. Draft | Write first version | Approved outline | Draft with claim markers |
| 5. Critique | Find weak logic or missing proof | Draft | Revision notes |
| 6. Revision | Improve clarity and support | Draft plus notes | Revised draft |
| 7. Final QA | Check format and risk | Revised draft | Pass/fix checklist |
Human review should happen after source summary, after critique, and before publication.
Structured handoff fields
Use fields like `claim`, `source name`, `evidence strength`, `missing context`, `risk`, and `recommended next step`. When dragging a PDF into a document agent and waiting for the page count to finish loading, it is tempting to trust the summary immediately. Don’t. Factual claims still need a source check before they go into a public report.
Common AI prompt chaining mistakes and fixes
The most common AI prompt chaining mistakes are operational, not cleverness problems. They happen when the chain looks tidy but the handoffs are vague.
- Vague-step sprawl: Too many steps with broad labels like “improve this” create noise. Fix it by giving each step one measurable job.
- Paragraph handoffs: Loose summaries make later agents infer structure. Fix it with tables, fields, outlines, or scored checklists.
- Skipped validation: Research and document-analysis outputs can sound finished before they are checked. Fix it with a verification step after extraction.
- Fake autonomy: A scripted chain is not the same as a self-directed agent. Fix expectations by documenting the workflow logic and escalation points.
- Downstream error drift: A bad first output can contaminate every later step. Fix it by stopping the chain and rerunning the failed step.
Detector score screenshots in chat can look decisive, but the flagged sentence still needs a person to read it. For higher-risk workflows, pair chaining with AI agent guardrails.
Verification checks for AI agent prompt chaining outputs
Verification checks should test source alignment, missing requirements, contradictions, format compliance, and risk level. Human review still matters for high-stakes publishing and business decisions because a clean chain can still produce a false conclusion.
The Stanford AI Index found that human performance still exceeds the best AI systems on several difficult benchmarks, which is a practical reminder to keep review steps in the loop. For deeper scoring methods, teams often pair prompt chains with AI agent evaluation.
Lightweight final QA checklist:
- Does every factual claim match an approved source?
- Did the output meet the requested format and audience?
- Are there contradictions between the draft and source summary?
- Did the chain mark uncertainty instead of hiding it?
- Does the risk level require legal, medical, financial, or executive review?
In a routed agent workflow, a document-analysis agent can check source extraction, and a detection or human review step can review text quality. The reviewer still owns the publication decision.